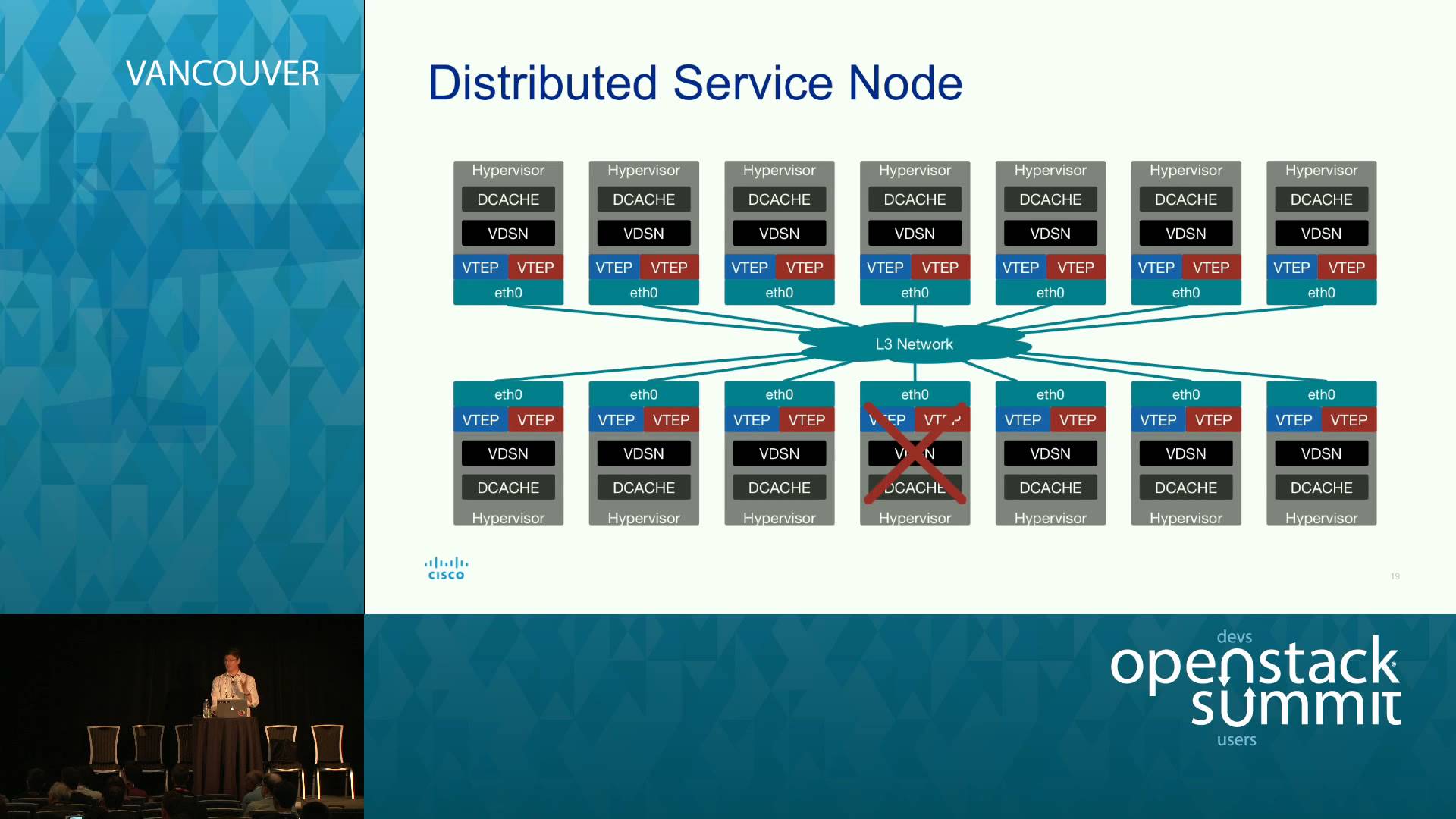
VXLAN is a point to point, UDP-based “tunneling” protocol, that enables L2 encapsulation over an L3 “undernet”, while also allowing up to 16 million Virtual Networks. One challenge with deploying VXLAN is that by default VXLAN requires multicast support for Broadcast, Unknown and Multi-cast packets. Often this is not possible in customer networks. An alternative… Continue reading Highly Available, Performant, VXLAN Service Node
Tag: HA
AURO: HA on a Public Cloud
In this demo, AURO will show how to create a highly available web-based application using their cloud platform built upon OpenStack.…Full session details here:
IPv6 impact on Neutron L3 High Availability
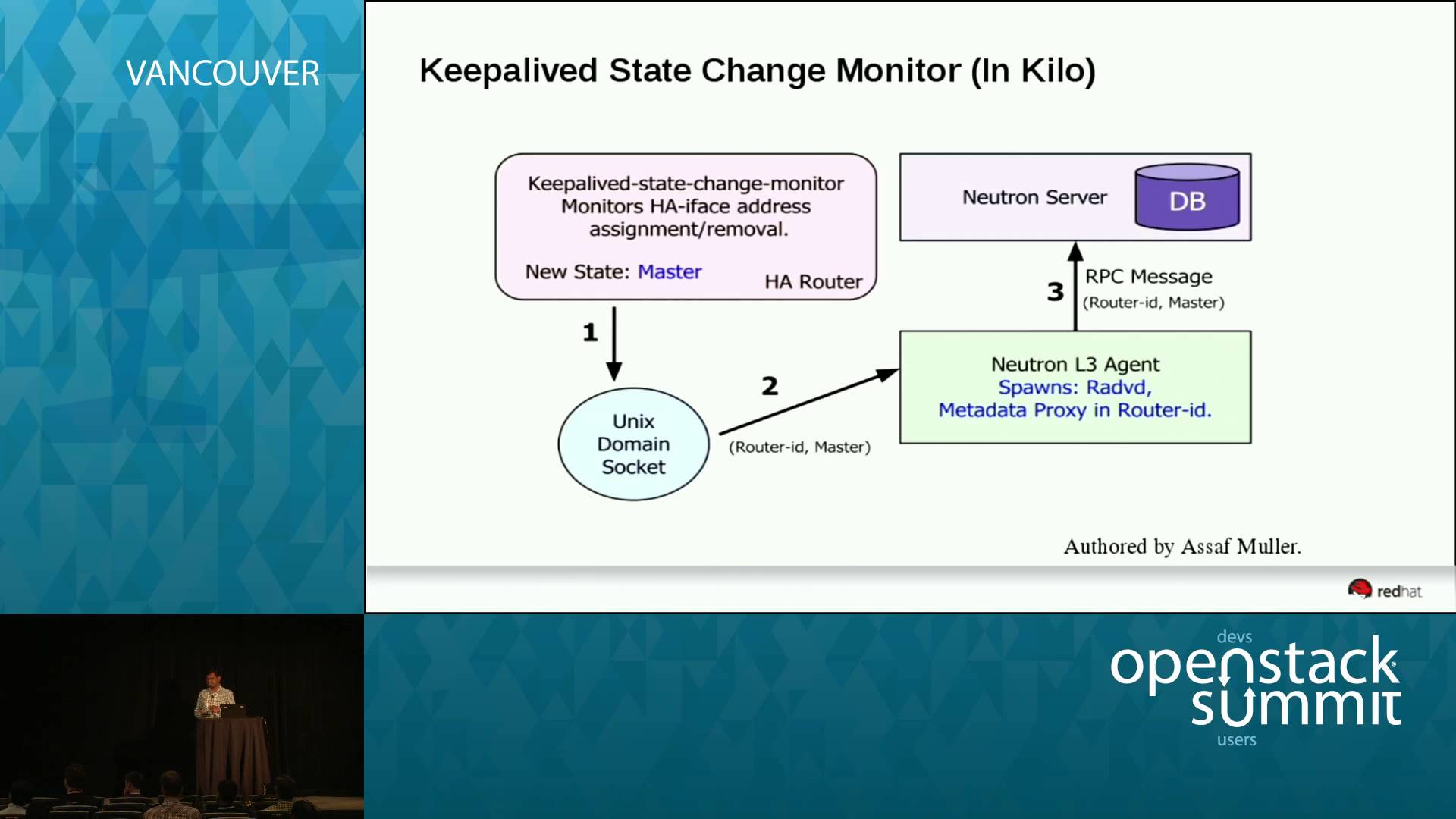
In OpenStack Juno release, L3 high availability in Neutron is implemented using Keepalived, which internally uses the VRRP protocol. It is an active/passive solution where a Keepalived instance is spawned in every router namespace and the instances communicate via a dedicated high-availability network, creating one per tenant. The IP addresses that are used in the… Continue reading IPv6 impact on Neutron L3 High Availability
Pacemaker: OpenStack’s PID 1

My name is David Vossel. I’m a core developer of the Pacemaker project and author of Pacemaker Remote. I want to share our success with scaling the Pacemaker cluster resource manager to meet the requirements necessary automate recovery of OpenStack controller and compute nodes. OpenStack’s architecture consists of a set of distributed components capable of… Continue reading Pacemaker: OpenStack’s PID 1
Providing OpenStack Service High-Availability Through Anycast Routing
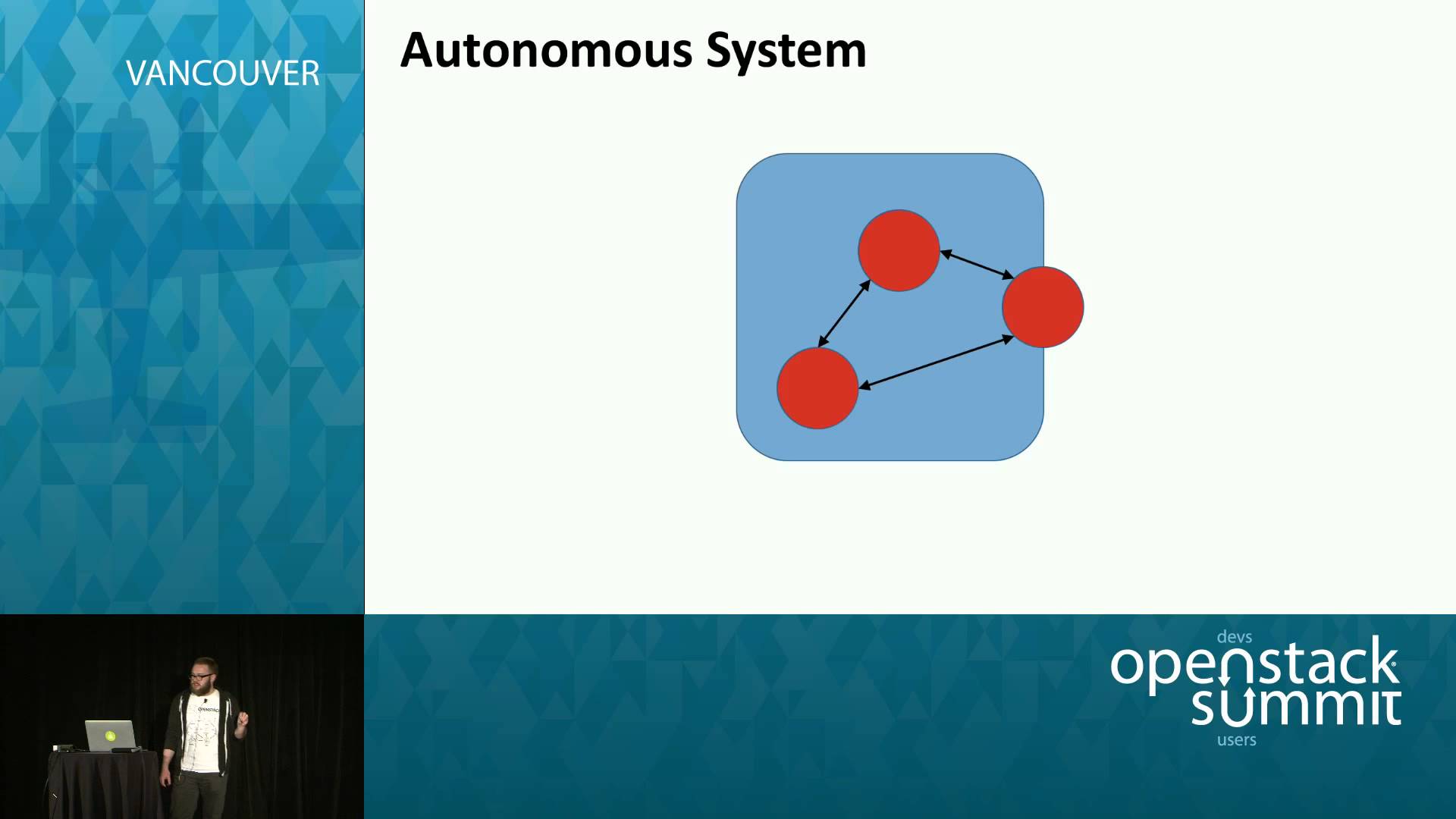
Service high-availability is a core concern for any operator running, or intending to run, a production OpenStack cluster. Current “best practices” call for the deployment of a full cluster stack (generally Corosync + Pacemaker) and / or load-balancers (generally HAProxy) to manage service state and failover. While this is appropriate for a subset of OpenStack… Continue reading Providing OpenStack Service High-Availability Through Anycast Routing
How to setup Multi Site SQL 2012 AlwaysOn Cluster with Two FCIs Across Datacenters?

In this how-to tutorial, we will look at implementing multi-node, multi-site SQL 2012 AlwaysOn Windows Server Failover Cluster (WSFC) with two Failover Cluster Instance (FCI) across two geographically dispersed datacenters for High Availability (HA) and Disaster Recovery (DR). I am currently working on a project where we’re going to upgrade from previous version of SQL… Continue reading How to setup Multi Site SQL 2012 AlwaysOn Cluster with Two FCIs Across Datacenters?
Turn off Network redundancy message when configuring VMware HA/DRS
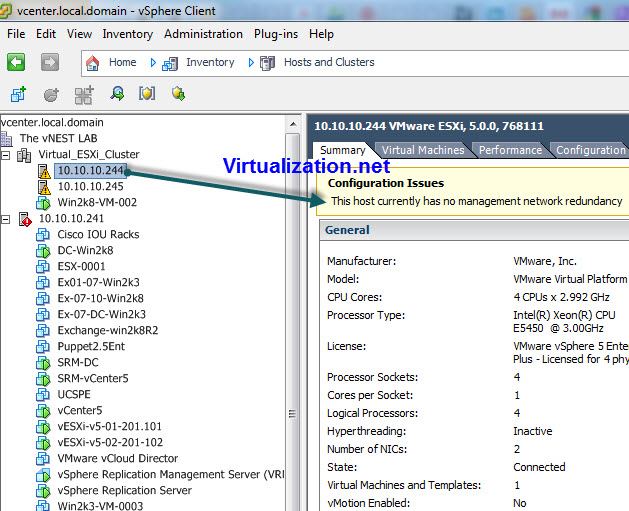
In my lab, when configuring VMware vSphere 5 HA/DRS in vCenter Server, you see the message under the “summary” tab in vSphere Client: Configuration issues: This host currently has no management network redundancy This message appears if VMKernel port does not have network redundancy configured at all or not configured properly. Normally, in production environment,… Continue reading Turn off Network redundancy message when configuring VMware HA/DRS
Avoiding the Biggest HA & Distributed Resource Scheduler Config Mistakes (BCO3420)
Avoiding the Biggest HA & Distributed Resource Scheduler Config Mistakes (BCO3420)
Everyone thinks HA and DRS are wonderful technologies. Yet bot…